In this series:
- CC Registry – What it’s all about (this post)
- CC Registry – Architecture
- CC Registry – Next steps
Wouldn’t it be nice if one day you could find an image online and know whether you can legally use that image and for what purpose? This is fundamentally what the Creative Commons registry is about.
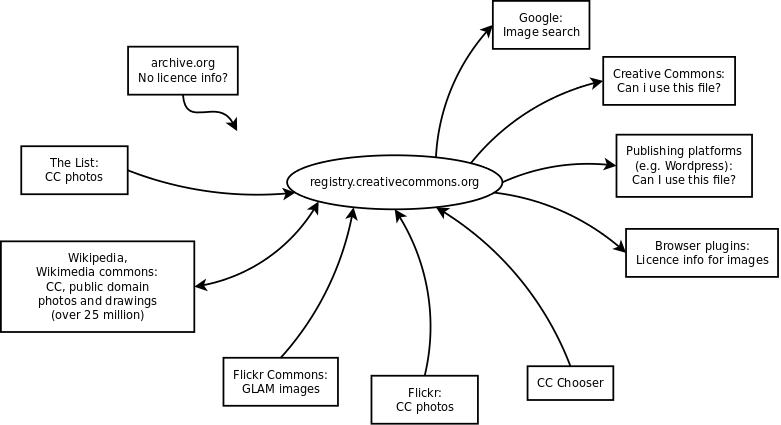
The concept is simple:
- Publishing tools (such as Flickr) automatically hash uploaded images and register them, including the name of the author, the licence, and a URL to the image.
- The registry holds the hashes, the other metadata, but not the image itself, only a thumbnail.
- Later this information is provided to anyone querying the service and can be displayed to the user in whatever way makes sense in that application.
The implementation is not so obvious, which is why we spent a couple of semesters at the Seneca Centre for Development of Open Technologies (CDOT) working on it.
There have been attempts at this in the past. None of them have gone very far, at least in part because they were trying to do too much. All past attempts were attempting to provide some kind of guarantee that the licence information in the registry is 100% correct – which of course is impossible.
Instead of doing that – we decided to leverage existing platforms (e.g. Wikimedia Commons, Flickr) because they already deal with this issue.