In this series:
- CC Registry – What it’s all about
- CC Registry – Architecture (this post)
- CC Registry – Next steps
I’ll now describe the components making the registry possible. All the source code for this is open source and available from GitHub.
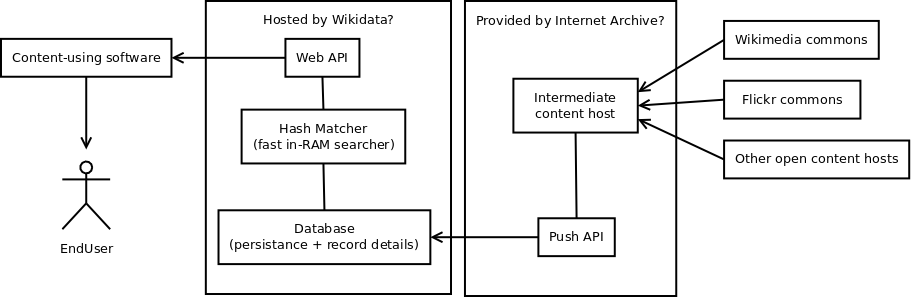
Data Source
When this goes into production – the images need to be hashed at the source. The bandwidth necessary to transfer all newly created images to a central server for registration would cost too much, there are literally millions of new images uploaded a day.
To accomplish that – one or more partnerships need to be set up. Either directly with new content hosts (Wikimedia Commons, Flickr, etc) or with an intermediary such as the Internet Archive.
Hashes
We’ve run quite a bit of testing on different perceptual hashing mechanisms:
- Perceptual hash comparison: pHash vs Blockhash: false positives
- Perceptual Hash for image
- Making images from alphabet characters
- Making sample images using ‘convert’ utility
- Perceptual hash test for text image
- Research about OpenSIFT
- Research about OpenSIFT 2
- Content Based Image Retreval : Concept and Projects
- Performance test of pHash
- MH Image Hash in pHash
- MH Image Hash in pHash 2 : test result
- Performance Test of pHash : MH Image Hash
- MVP Tree for similarity search
- MVP Tree with MH Hash for Image Search
- MH Hash, MVP-Tree indexer/searcher for MySQL/PHP
- Pastec test method and result
- Pastec analysis
- Pastec Test for real image data
- Pastec Test for Performance
- DCT Hash matching quality for resized images
- DCT HASH MATCHING QUALITY FOR RESIZED IMAGES 2
The result was obvious – the DCT algorithm from pHash won. What it does is create a 64bit hash for an image of any original size and complexity. I was worried about too many false positives but the results were very good, in the range of under 1%.
It’s not the fastest algorithm but it only takes a couple of seconds to compute a hash and because of its small size – it can be stored in RAM for fast searches.
Database
The data is persisted in an off-the-shelf MySQL database. I was worried that querying from a hundred million records would tax the system too much but a simple select by primary key takes no time at all so we didn’t investigate other options.
The persistent database stores all the metadata, but not the thumbnails. Those take too much space, so each of those is stored as a regular file on an XFS filesystem on a rotating drive. The path to the thumbnail is stored in the database.
Hash Matcher
This part needs speed. For each query we need to run an operation against every record in the database. Using any existing technology for that would have been too slow so we developed our own.
The hash matcher loads pairs of (DBprimaryKey, hash) into RAM as a singly-linked list. That’s 24 bytes per record. I made sure that a server with 32GB of ram would have enough memory for 100 million records and it does, that’s way more than enough.
The matching operation is performed using a single-instruction POPCNT operation via the GCC __builtin_popcount(). One of my biggest worries was the time it will take per query, but it’s very fast, under one second against a hundred million records on a quad-core Xeon E5-1603 (inexpensive workstation CPU).
Internal API
The hash matcher is not externally accessible, it’s used on localhost via a unix domain socket. See daemon/readme.md and daemon/interface.md for usage info.
External API
The service is accessible by the world via a web API. This is implemented in PHP and is documented here.
Client Software
We built a demo page (that’s also written in PHP but is separate from the API) to show that this system works. It has over a million images (that’s what we had the bandwidth to download) from Wikimedia and Flickr.